# An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- CNN を依存せず純粋な Transformer で画像認識を行う ViT を提案し,うまく行けることを示した.
- 大量のデータで事前トレーニングし中小規模データに遷移すると優れた結果が出て計算コストが大幅に少なくなる.
# アブスト
Transformer アーキテクチャは自然言語処理の標準化された基準となったが,そのコンピュータービジョンにおける応用はまた制限されている.視覚では,Attention は畳み込みネットワークと組み合わせで使うか,畳み込みネットワークの全体的構造をいじしながらネットの特定構成要素を置き換えるために用いられる.我々は,CNN への依存は必要ではないことと画像パッチのシーケンスに直接適用される純粋な Transformer が画像分類タスクにうまく行けることを示す.大量のデータで事前トレーニングし,複数の中規模または小規模の画像認識ベンチマーク (ImageNet, CIFAR-100, VTAB, etc.) に遷移される際に,最先端の畳み込みネットワークと比較して優れた結果を達成すると同時に,トレーニングに必要な計算資源が大幅に少なくなる.
# イントロ
自己注意力機構,特に Transformers (Vaswani et al., 2017) は自然言語処理の定番モデルとなっている.主要な手法は大規模テキストコーパスで事前学習を行いより小さな特定タスクのデータセットで微調整することである.(Devlin et al.,2019).Transformers の計算効率と拡張性のおかげで,100B のパラメータを超える空前のサイズを有する訓練モデルが可能となった (Brown et al.,2020;Lepikhin et al.,2020).モデルとデータセットの拡大と伴いパフォーマンスが飽和する兆候はまだない.
しかしながら,コンピュータービジョンでは,畳み込みアーキテクチャはまた主導的である (LeCun et al.,1989;Krizhevsky et al.,2012;He et al.,2016).NLP の成功に啓発され,CNN-like アーキテクチャと自己注意力機構を組み合わせてみた研究もあるし (Wang et al.,2018;Carion et al.,2020),畳み込みを全部置き換える研究もある (Ramachandran et al.,2019;Wang et al.,2020a).後者のモデルは理論的には効率ですが,特殊な注意力パラメータの使用で最新のハードウェアアクセラレータではまだ効果的スケーリングされていない.したがって,大規模画像認識では,従来の ResNet-like アーキテクチャは依然として最先端である (Mahajan et al., 2018; Xie et al., 2020; Kolesnikov et al.,2020).
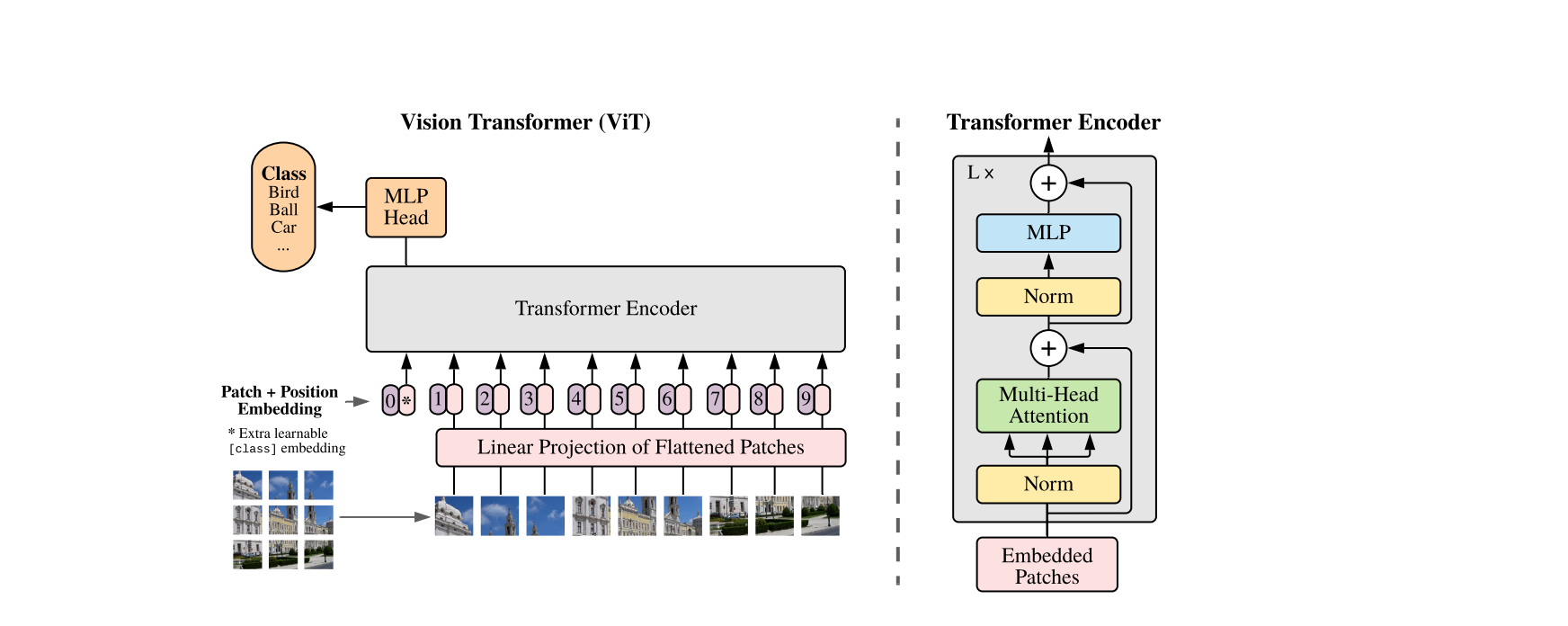
NLP における Transformer スケーリングの成功に啓発され,我々は最小限の変更で標準 Transformer を直接に画像に応用する.そのため,我々は 1 枚の画像をパッチ化しそれらのパッチ画像の線形エンベディングのシークエンスを Transformer の入力とする.パッチ画像は NLP 応用におけるトークンと同じように処理されている.我々は教師あり画像分類のモデルで訓練する.
強い正則化を使わず ImageNet 等の中規模データセットで訓練した場合,これらのモデルは同等のサイズの ResNet よりも精度が数パーセンテージでやや低かった.この一見落ち込んだ結果が良そうされるのである:Transformers は CNN の固有帰納バイアスを一部欠けている.例えば,平行移動等価性と局所性である.したがって,不十分な量のデータで訓練して場合,うまく汎化できない.
しかしながら,大規模データセット (14M-300M 画像) でモデルを訓練すると状況が変わった.大規模な訓練が帰納バイアスに勝ることが分かった.十分な規模で事前学習しデータの少ないタスクに遷移される場合,我々の Vision Transformer (ViT) は素晴らしい結果を得られた.公開データの ImageNet-21k または Google 社内の JFT-300M で事前学習した場合,ViT は複数の画像認識ベンチマークで SOTA に近くあるいはそれを超える結果である.特に,最も良いモデルが ImageNet で 88.55%,ImageNet-ReaL で 90.72%,CIFAR-100 で 94.55%,VTAB の 19 タスクで 77.63% の Accuracy に達成した.
# 関連研究
Transformers は Vaswani et al.(2017) に機械翻訳のため提案された.それが様々な NLP タスクで SOTA となっていた.Transformer に基づいた大規模モデルは,多くの場合,大規模コーパスで事前学習され,目の前のタスクに合わせて微調整される:BERT (Devlin et al.,2019) はノイズ除去の自己教師なり事前学習を用いたことに対して,GPT は言語モデリングを事前学習タスクとして使う (Radford et al., 2018; 2019; Brown et al., 2020).
自己注意力機構を単純に画像に適用するには,各ピクセルが他の全てのピクセルに注意を向ける必要がある.ピクセル数の 2 次コストを用い,これは現実的な入力サイズにスケーリングしない.したがって,画像処理の文脈で Transformers を適用するには,過去いくつかの試しがあった.Parmar et al.(2018) は全局的を代わりに局所近傍のみで各 query ピクセルに自己注意力を適用した.このような局所 multi-head dot production 自己注意ブロックは,畳み込みを完全に置き換えることができる (Hu et al., 2019; Ramachandran et al., 2019; Zhao et al., 2020).他研究では,スパース Transformers (Child et al., 2019) が画像に適用できるように全局自己注意機構にスケール可変な近似法を採用する.注意力をスケーリングする別の方法は,様々なサイズのブロック (Weissenborn et al., 2019) に適用することである.極端的場合では,個々の軸に沿ってのみ適用する (Ho et al., 2019; Wang et al., 2020a).これらの特集な注意力アーキテクチャはコンピュータービジョンタスクにおいて有望な結果を示しているが,ハードウェアアクセラレータで効率的実装するには複雑な工程が必要である.
私たちの研究に最も関連しているのは Cordonnier et al. (2020) のモデルである.このモデルは入力画像からサイズ 2 2 のパッチを抽出し,その上に full-attention を適用する.このモデルは ViT に非常に似ているが,私たちの研究は更に進んで大規模事前学習により普通の Transformers が SOTA CNNs と競合する (またはそれよりも優れた) ものになることを示している.さらに,Cordonnier et al. (2020) はサイズ 2 2 ピクセルの小さいパッチを用いた.これにより,低解像度画像のみにモデルを応用でいるようになってしまった.それに対して,我々は中解像度画像にも対応する.
自己注意力機構と畳み込みニューラルネットワーク (CNNs) の組み合わせにも多くの関心が寄せられている.例えば,画像分類に特徴マップの拡張 (Bello et al., 2019).また,自己注意力機構を用いた CNN 出力をさらに調整する処理,例えば,目標検出 (Hu et al., 2018; Carion et al., 2020),動画処理 (Wang et al., 2018; Sun et al., 2019), 画像分類 (Wu et al., 2020), 教師なし目標発見 (Locatello et al., 2020),或いは統一されたテキスト - ビジョンタスク (Chen et al., 2020c; Lu et al., 2019; Li et al., 2019).
もう一つの最近の関連モデルは image GPT (iGPT)(Chen et al., 2020a).iGPT は画像解像度と色空間を削減し,画像ピクセルに Transformers を適用する.このモデルは生成モデルとして教師なしで訓練され,結果として得られる表現は分類パフォーマンスのために微調整または線形的探索をでき,ImageNet で最大精度の 72% を達成する.
我々の研究は標準の ImageNet データセットよりも大きなスケールで画像認識を調査する論文のコレクションの増加
(つづく)
# 専門用語和英対照
| 日本語 | 英語 |
|---|---|
| 標準化された基準 | de-facto standard |
| 微調整 | fine-tune |
| 帰納バイアス | inductive bias |
| 平行移動等価性 | translation equivariance |
| ノイズ除去 | denoising |
| 2 次コスト | quadratic cost |
| 普通の Transformers | vanilla transformers |