# SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
- 大きい畳み込みカーネルで Transformer の attention を置き換えることで Segformer を改善していく.
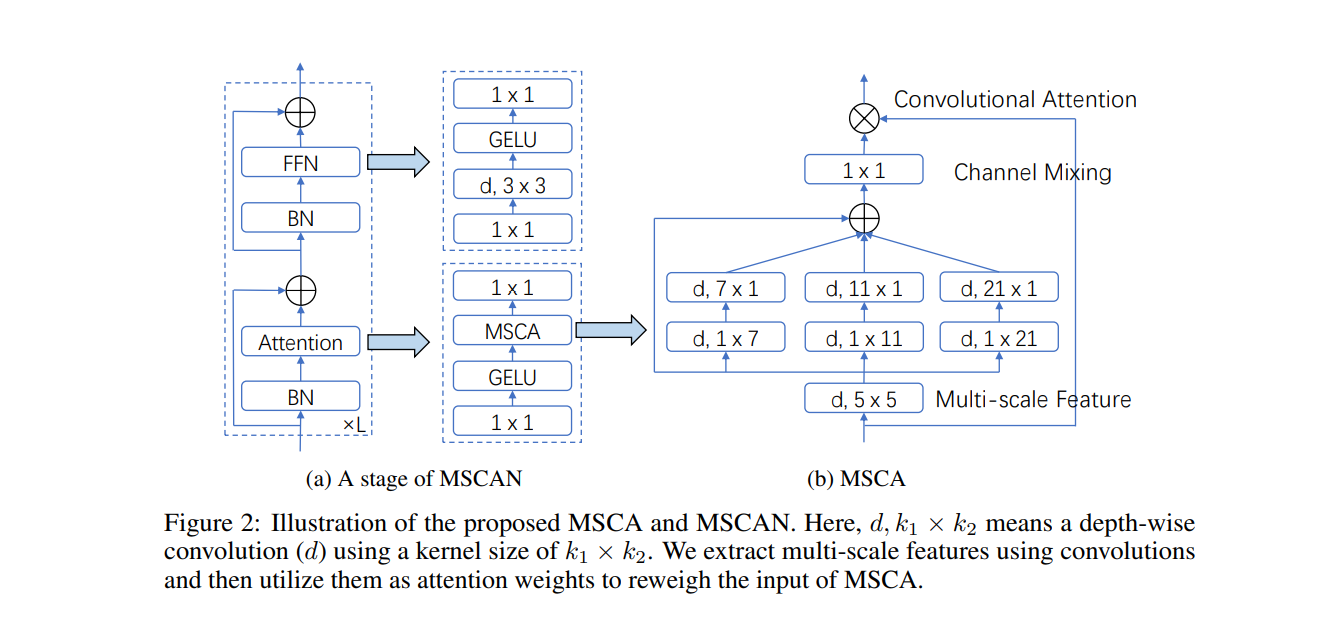
- multi-scale 畳み込み特徴を用いて空間的 attention を実現する.
- シンプルなかつコスト低い畳み込みを用いて ViT よりも良いパフォーマンスであった.
# アブスト
我々は SegNeXt を提案する.SegNeXt は,セマンティック・セグメンテーションにシンプルな畳み込みネットワークである.最近 Transformer に基づいたモデルは,空間情報のエンコーディングにおける効率的 self-attention で,セマンティック・セグメンテーション分野の首位となる.この研究で,畳み込み attention は,文脈上情報をエンコードするに,Transformer の self-attention 機構よりも効率的かつ効果的な手法を示している.成功したセグメンテーション・モデルが持つ特性を再検討することで,セグメンテーション・モデルのパフォーマンス向上につながるいくつかの重要な要素を発見した.これは安価な畳み込み演算を使用する新しい畳み込み attention ネットワークを設計する動機になる.付加機能がなければ,我々の SegNeXt は,ADE20K,Cityscapes,COCO-Stuff,Pascal VOC,Pascal Context,iSAID などの一般的なベンチマークで,以前の最先端の方法のパフォーマンスを大幅に改善する.特に,SegNeXt は NAS-FPN を用いた EfficientNet-L2 よりも優れたパフォーマンスを発揮し、Pascal VOC 2012 テスト・リーダーボードで 1/10 のパラメーターのみを使用して 90.6% の mIoU を達成している.SegNeXt は ADE20K データセットの最先端の方法と比較して,同等またはより少ない計算で約 2.0% の mIoU の改善を達成する.コードが利用可能です.
# イントロ
(つづき)
# 専門用語和英対照
| 日本語 | 英語 |
|---|---|