# SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
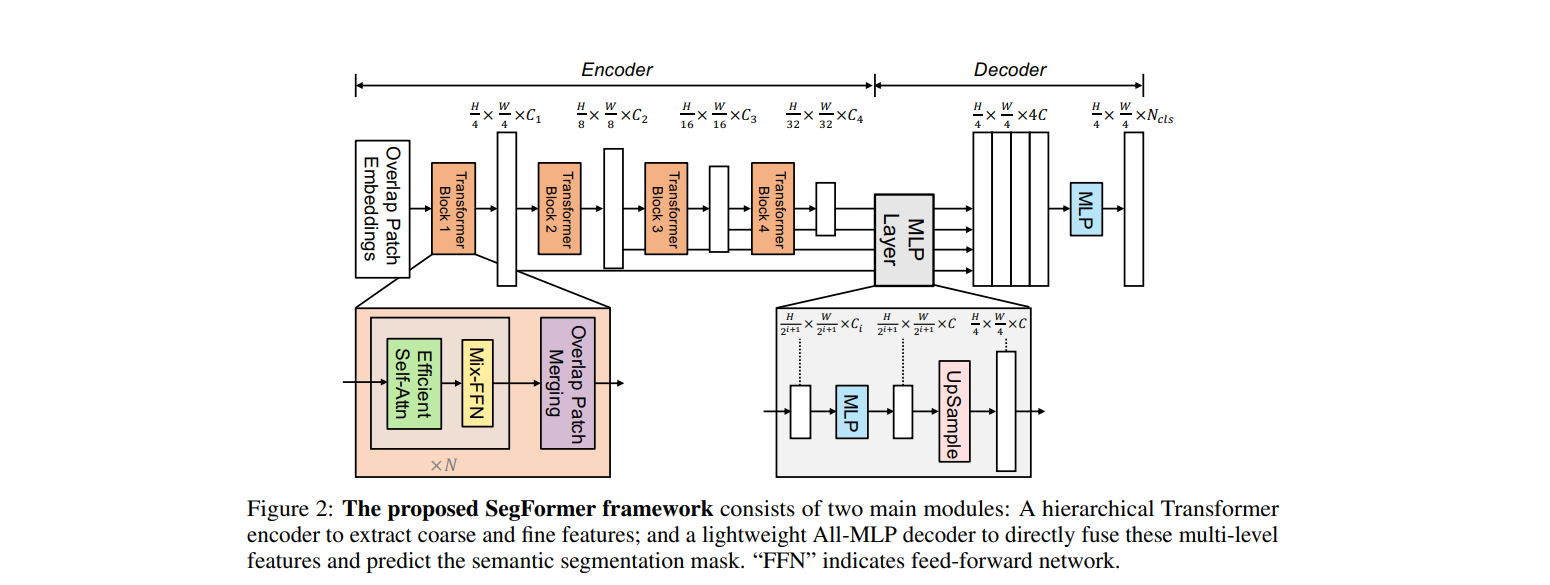
- 位置エンコーダを使わず階層的構造を有する Transformer によって性能低下に繋がる位置エンコーダの補間を回避できる.
- デコーダは MLP のみからなることで軽量となり効率的受容野をもたらしたことを示した.
# アブスト
我々は Segformer を提案する.Segformer は,Transformer を軽量の多層パーセプトロン (MLP) デコーダーと統合する,シンプルで効率的かつ強力なセマンティック・セグメンテーション・フレームワークである.Segformer は 2 つの魅力的特徴がある:1)Segformer はマルチスケール特徴を出力する,新しい階層的構造の Transformer エンコーダを備えている.位置エンコーディング(positional encoding)は必要としないため,テストの解像度がトレーニングのと異なる場合に,性能の低下に繋がる位置コード(Positional code)の補間を回避できる.2)SegFormer は複雑なデコーダーを回避する.提案された MLP デコーダーは,様々なレイヤーからの情報を集約し,局所的 Attention と全局的 Attention の両方を組み合わせ,強力な表現を与える.このシンプルで軽量な設計が Transformer による効率的なセグメンテーションの鍵であることをす.アプローチをスケールアップし,SegFormer-B0 から SegFormer-B5 までの一連のモデルを取得し,従来法よりも大幅に優れたパフォーマンスと効率を実現する.例えば,ADE20K では SegFormer-B4 が 64M パラメータで 50.3% の mIoU を達成し,以前の最良方法よりも 5 分の 1 小さく,2.2% 優れている.我々の最も良いモデルである SegFormer-B5 は,Cityscapes の検証セットで 84.0% の mIoU を達成し,Cityscapes-C で優れた zero shot のロバスト性を示している.コード
# イントロ
(つづき)
# 専門用語和英対照
| 日本語 | 英語 |
|---|---|